本文将讨论 GKE 中的 5 个功能,您现在可以使用这些功能来优化您的集群。要开始在 GKE 中测试这些,请查看交互式教程以开始使用标准和自动驾驶仪集群。
如果您从组织中的 Kubernetes 集群上运行工作负载中发现价值,那么您的足迹很可能会增加——无论是通过更大的集群还是更多的集群。
无论采用哪种方法,有一件事是肯定的:您将拥有更多需要付费的资源。你知道他们怎么说——更多的资源,更多的问题。跨集群拥有的资源越多,确保有效使用它们就变得越重要。
Google Kubernetes Engine 具有许多内置功能,作为集群管理员,您可以使用这些功能来导航优化 GKE 中资源使用的持续旅程。
1、控制台中的集群视图成本优化
如果您不知道从哪里开始优化您的集群,最好的起点是寻找一个突出的大问题。通过查看跨越所有集群的视图,这可能是最明显的。
在 GKE 中,谷歌在控制台中内置了一个集群级成本优化选项卡,其中包含丰富的信息,否则您自己收集起来可能很麻烦。
您可以找到它,如下图所示:
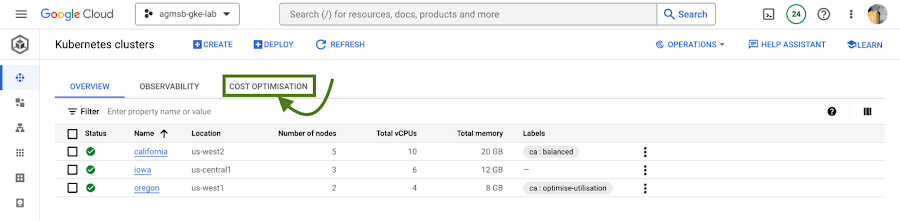
图 1 – 导航到云控制台中的成本优化选项卡
导航到此选项卡后,您会看到时间序列可视化。
对于 GKE 标准集群,此可视化是一种时间序列表示,显示项目中所有集群的 CPU 和内存的三个关键维度:
- Total CPU/Memory allocatable- 可分配给用户工作负载的 CPU 数量或 GB 内存
- Total CPU/Memory request – 用户工作负载请求的 CPU 或 GB 内存
- Total CPU/Memory usage- 用户工作负载的 CPU 数量或 GB 内存的实际使用情况
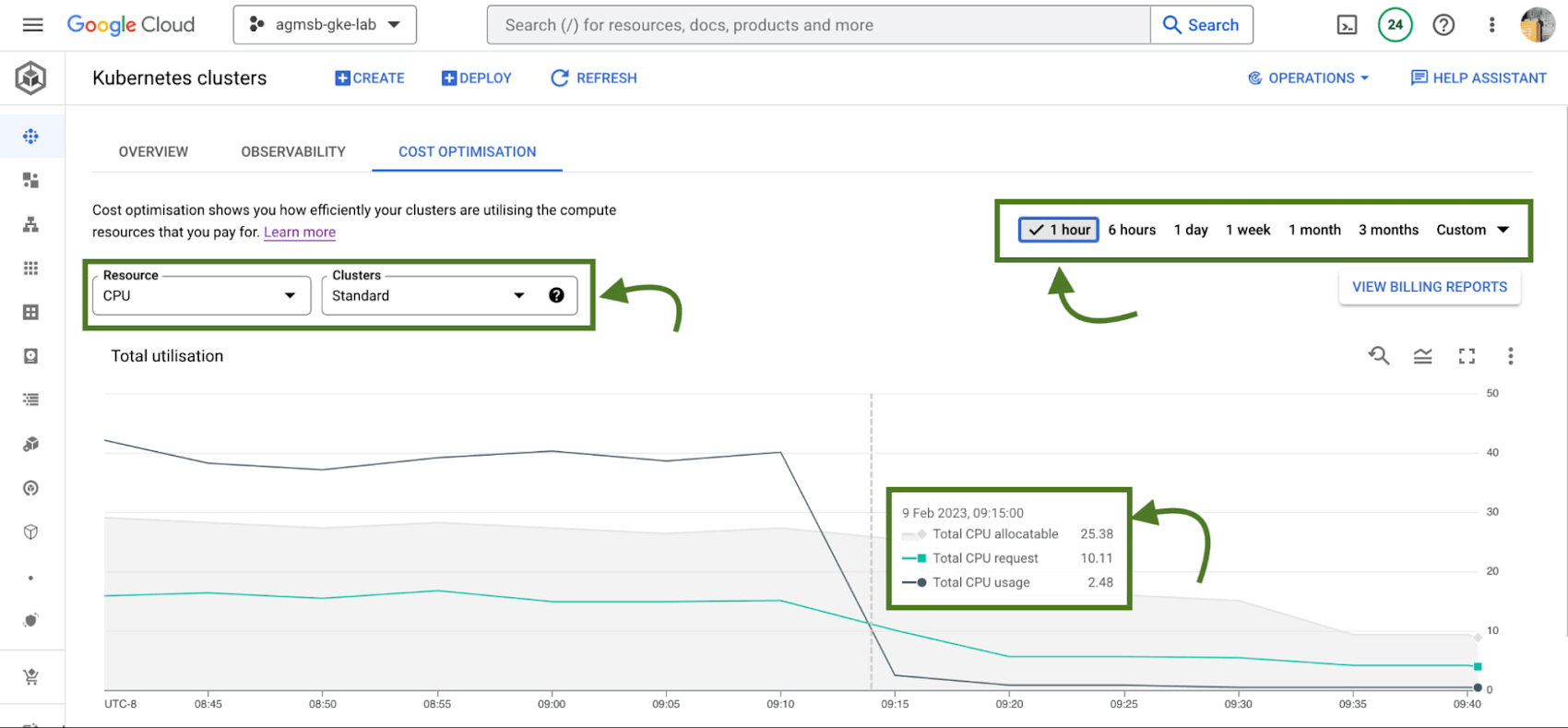
图 2 – 指定窗口内所有标准 GKE 集群中 CPU 或内存的可分配、请求和使用时间序列数据
分析这些相互之间的关系有助于确定重要优化问题的答案,例如:
- 谷歌的 GKE 标准集群中是否有太多可分配的 CPU 和内存闲置?如果是这样,谷歌是否可以做一些事情,比如重新评估谷歌在节点池中使用的机器类型?通过将更高百分比的可分配资源分配给 Pod 请求,这可以帮助谷歌对集群进行 bin pack。
- 在谷歌的 GKE 标准集群中运行的工作负载是否需要过多未使用的 CPU 和内存?如果是这样,谷歌可以做一些事情,比如与工作负载所有者合作来调整请求吗?这可以帮助谷歌调整工作负载大小,方法是将请求设置为更接近地反映预期使用情况。
如果谷歌使用 GKE Autopilot,这个时间序列可视化看起来会略有不同,如下图所示:
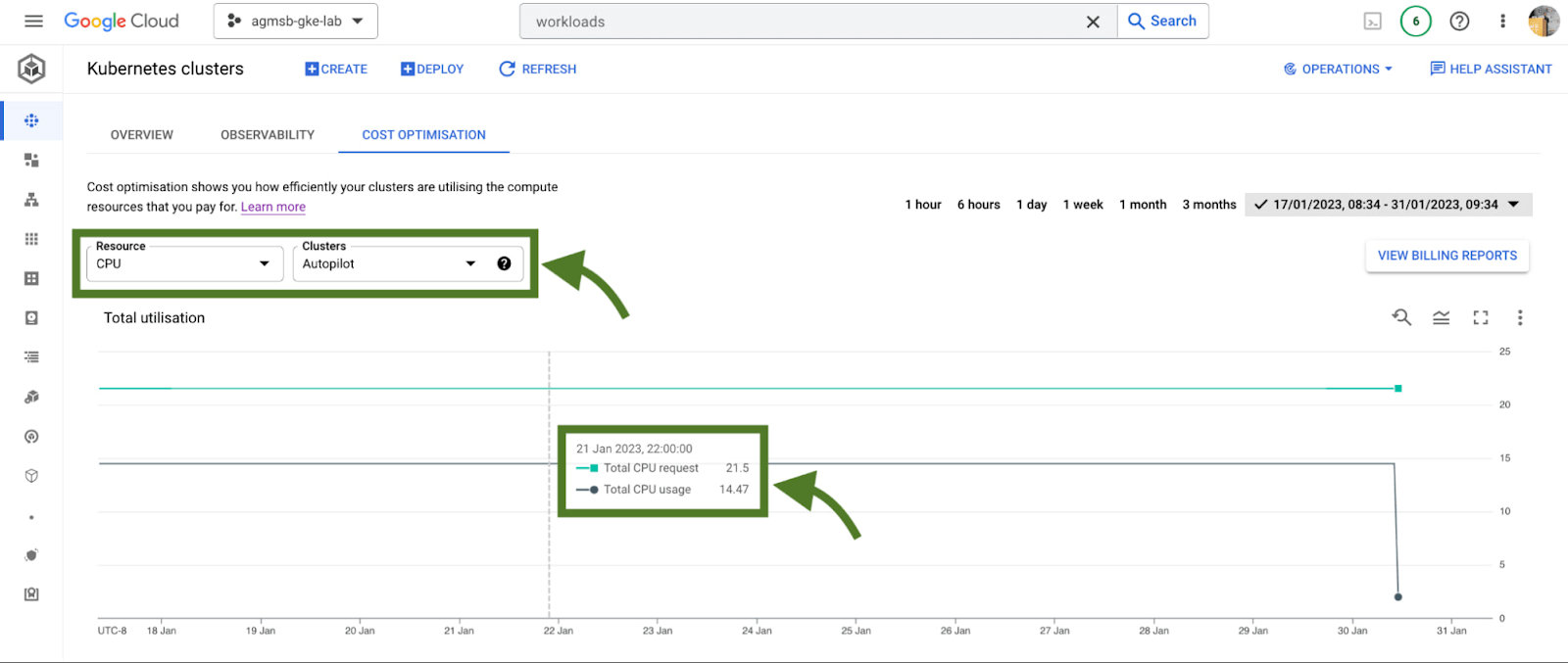
图 3 – 所有 GKE Autopilot 集群中跨 CPU 或内存的请求和使用时间序列数据
对于 GKE Autopilot 集群,谷歌只能查看Total CPU/Memory request和Total CPU/Memory usage数据。但实际上这里什么都没有丢失!
在 Autopilot 集群中,您只需根据请求为每个 Pod 付费;Autopilot 自动处理基础设施的配置,根据您将 Pod 请求设置为什么,为谷歌提供可分配的资源。当谷歌交易节点配置的所有权时,谷歌也交易控制权以在该层进行优化。
对于集群管理员而言,此信息可能会激发行动,例如深入研究各个集群或与工作负载团队会面以解决他们为工作负载设置的请求和限制。在谷歌的研究中,这可能是许多团队优化的最具影响力的领域。谷歌将在本博客中深入探讨 GKE 如何启用此练习。
当沿着这些路径前进时,拥有财务数据有助于量化优化对业务的影响。自行收集此信息可能需要一些工作(对于某些人来说,还需要大量电子表格!),但幸运的是 GKE 具有另一个本机功能,可帮助您轻松访问此信息。
2、GKE 成本分配
GKE 成本分配是一项原生 GKE 功能,它将工作负载使用情况与 Cloud Billing 及其报告集成在一起,使您不仅可以在每个集群级别,而且可以在每个 Kubernetes 命名空间或每个 Kubernetes 标签级别查看和提醒计费。
它必须在您的集群上启用才能运行,因此如果您正在使用现有的 GKE 集群并希望启用它,请在设置适当的地区或区域后使用以下 gcloud 命令:
$ gcloud beta container clusters create $CLUSTER_NAME \
–enable-cost-allocation
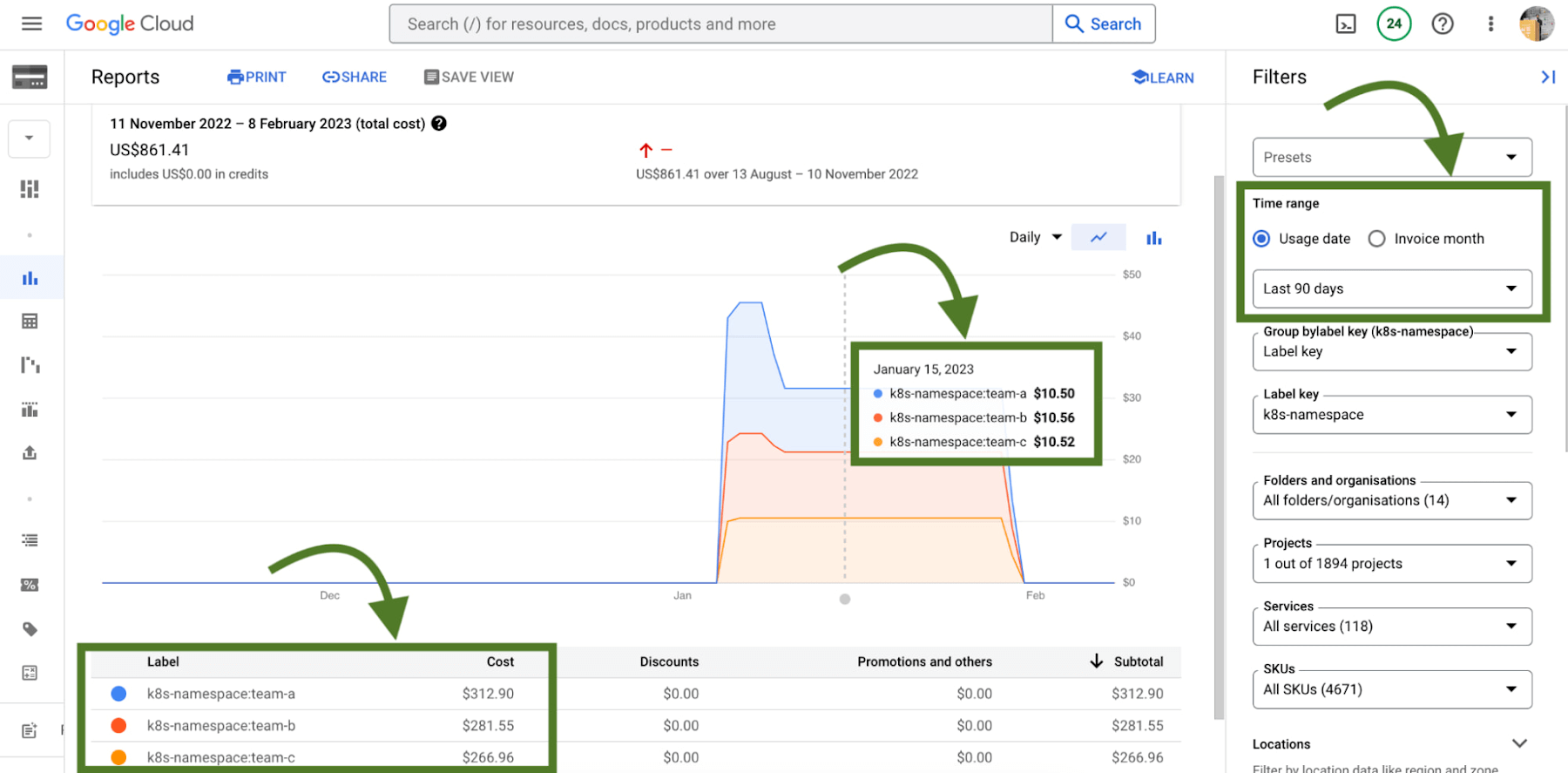
图 4 – 启用成本分配的 GKE 集群中命名空间的 Cloud Billing 报告
如果没有 GKE 成本分配,集群及其可能运行的所有不同工作负载的财务影响会有些模糊。由于集群是计费中最详细的级别,因此找到要优化的区域甚至执行分摊和计费都是一项挑战。
随着命名空间和标签不断涌入账单报告,您现在可以了解工作负载在 Kubernetes 中定义的 CPU/内存请求的成本。一个警告 – 当您使用命名空间和标签来逻辑定义和组织团队及其工作负载时,这最有效。
这种集成还提供了更广泛的优化图景——因为 GKE 通常不在孤岛上!理论上,团队命名空间中的工作负载可以使用外部支持服务,如 Cloud Memorystore,这也是其使用的关键部分。
由于 Cloud Billing 数据具有所有GCP 服务,谷歌现在可以跨命名空间及其相应的支持服务进行过滤和查询。
3、控制台中的工作负载视图成本优化
一旦您确定了您可能想要与之合作的团队,GKE 会在工作负载级别提供一个成本优化选项卡,然后您可以在其中开始向下钻取并确定可以通过称为“工作负载调整大小”的练习来优化的特定工作负载. 这是确保 Pod 请求更接近地反映其预期用途的行为。

图 5 – GKE 成本优化选项卡下的单个工作负载条形图
正如您在此处看到的,谷歌提供了条形图来表示使用情况、请求和限制之间的关系。
- 深绿色:CPU/内存使用率
- 浅绿色:CPU/内存请求
- 灰色:CPU/内存限制
- 黄色:CPU/内存使用率超过请求的场景
您还可以将鼠标悬停在每个单独的工作负载条形图上,以在屏幕上显示该数据的小型报告。类似于集群视图成本优化选项卡,您可以向下过滤到自定义时间窗口;谷歌建议在大于一个小时(即一天、一周、一个月)的窗口中查看此数据,以潜在地发现可能会被混淆的昼夜或每周模式。
在这些图表的前面的屏幕截图中,谷歌可以指出一些可能对您来说很突出的模式:
- 如果谷歌在条形图上有太多浅绿色堆叠在深绿色之上,谷歌可能会有过度配置的工作负载。
- 如果谷歌有一个黄色的条,谷歌有一个请求没有设置足够高的工作负载,这可能是稳定性/可靠性风险 – 在其节点上消耗额外的资源并且如果达到其限制则可能被限制或 OOMKilled。
- 如果谷歌有一个全是深绿色的条,这意味着谷歌没有为工作负载设置请求 – 这不是最佳实践!设置这些请求。
有了这些信息,就可以更轻松地快速识别需要为成本优化或稳定性和可靠性调整请求和限制的工作负载。
4、调整工作负载请求的建议
在谷歌需要增加或减少 CPU/Memory 请求的场景中,知道它需要做比知道它需要如何做更容易。谷歌应该将请求设置为什么?

图 6 – 针对工作负载的 CPU 和内存的 Vertical Pod Autoscaler 建议
GKE 将来自 Kubernetes Vertical Pod Autoscaler (VPA) 的建议直接集成到其工作负载控制台中,目前适用于集群中的所有部署。Actions > Scale > Scale compute resources在查看特定工作负载的页面时, 您可以通过导航到菜单找到它。
重要的是要记住,这些建议只是建议。它们基于历史使用数据,因此在查看这些值时,重要的是要与工作负载所有者合作,看看这些建议是否适合合并到他们各自的 Kubernetes 清单中。
5、成本估算和集群创建设置指南
最后,如果您刚刚开始使用 GKE,并且希望从正确的、优化的角度开始,谷歌已将工具整合到 GKE 集群创建页面中。

图 7 – 集群创建设置指南 (1) 和集群创建成本估算 (2)
首先,谷歌有一个设置指南,可以帮助您创建一个固定的 GKE 标准集群,其中已经启用了谷歌在此讨论的一些功能,例如 GKE 成本分配和 Vertical Pod Autoscaler。
其次,谷歌还有一个成本估算面板,它会根据您的 GKE 标准集群的配置向您显示估算的每月成本。如果您希望集群扩大和缩小规模,这甚至可以帮助您获得一系列潜在成本!
怎么办?
跨一组 GKE 集群的优化可能包括一些需要考虑的领域——这不是一次性任务!相反,这是一个持续的旅程,集群管理员、工作负载所有者,甚至计费经理都参与其中。GKE 提供的工具可以让这个旅程和过程变得更轻松,并让正确的数据和见解触手可及。
要熟悉 GKE 中的这些功能,请查看谷歌的交互式教程以开始使用标准和自动驾驶集群。
您还可以在以下视频中观看展示其中大部分功能的演示: