统一、受管控的数据到 AI 体验
-
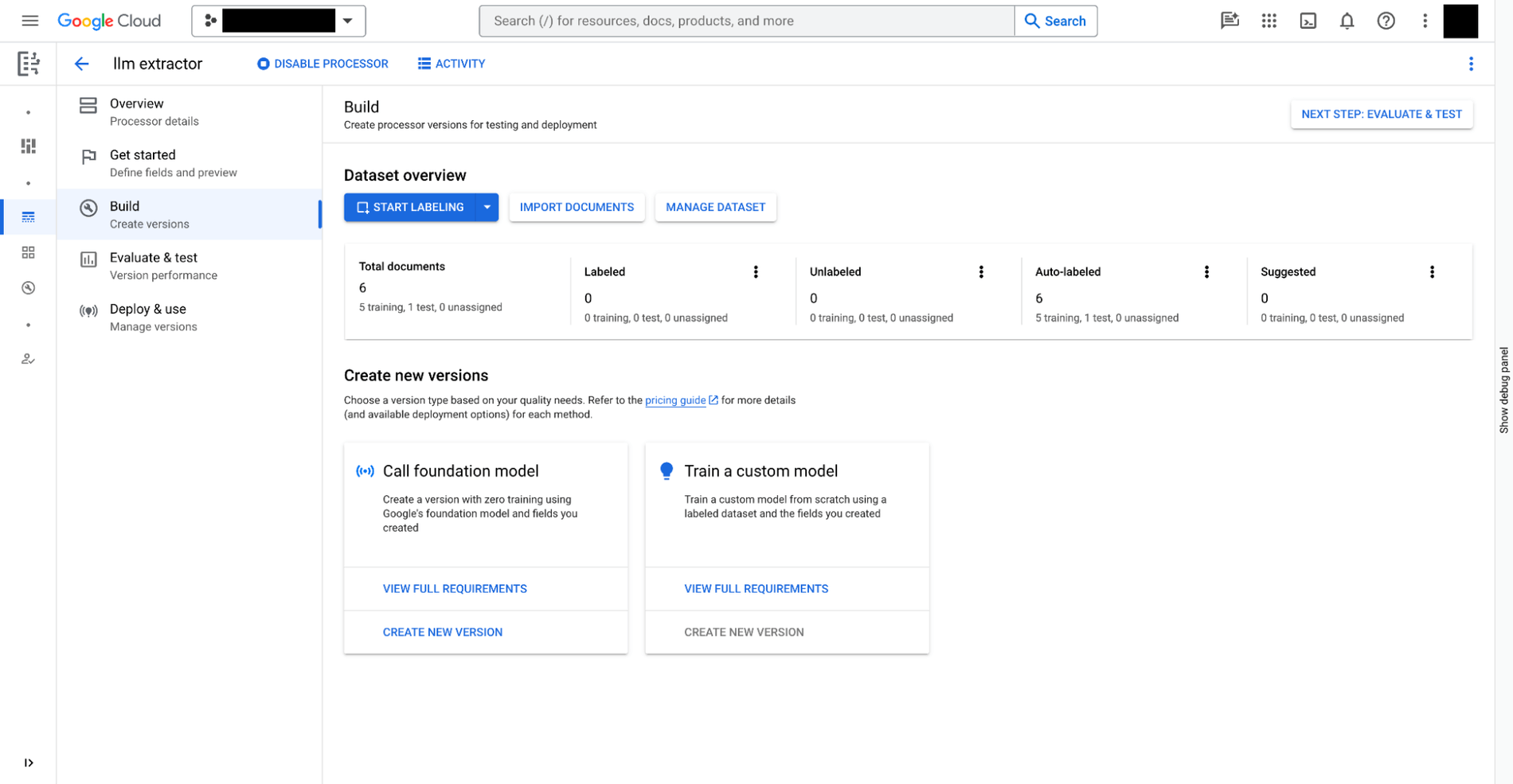
定义您需要从文档中提取的数据。这被称为文档架构,存储在每个自定义提取器的版本中,并可从 BigQuery 访问 -
提供带有注释的额外文档作为提取的样本 -
根据 Document AI 提供的基础模型,对自定义提取器进行训练
- 使用 SQL 为提取器注册一个 BigQuery 远程模型。该模型能理解文档架构(上面创建的),调用自定义提取器并解析结果。
- 使用 SQL 为存储在 Cloud Storage 中的文档创建对象表。您可以通过设置行级访问策略在表中管理非结构化数据,从而限制用户对特定文档的访问,并因此限制 AI 对隐私和安全的影响。
- 使用 ML.PROCESS_DOCUMENT 函数在对象表上提取相关字段,通过对 API 端点进行推断调用。您还可以在函数之外使用“WHERE”子句来过滤提取的文档。该函数返回一个结构化表,其中每一列都是一个提取的字段。
- 将提取的数据与其他 BigQuery 表进行连接,结合结构化和非结构化数据,生成业务价值。
以下示例展示了用户体验:
# Show a screenshot of curating Doc AI custom extractor in Workbench
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.receipt_table`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = ‘SIMPLE’,
uris = [‘gs://my_bucket/path/*’],
metadata_cache_mode= ‘AUTOMATIC’,
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.invoice_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = ‘CLOUD_AI_DOCUMENT_V1’,
document_processor=’projects/…/locations/us/processors/…/processorVersions/pretrained-invoice-v1.3-2022-07-15′
);
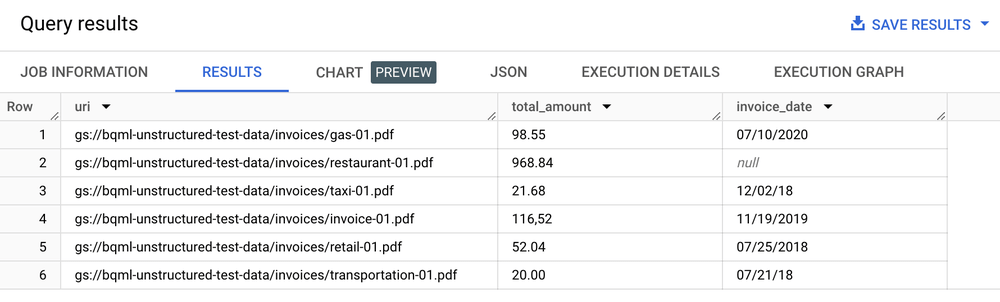
# Invoke the registered model over the object table to parse PDF expense receipts
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.invoice_parser`,
TABLE `my_dataset.receipt_table`)
WHERE content_type = ‘application/pdf’;
结果表
文本分析、摘要和其他文档分析用例
- 使用 BigQuery ML 进行文本分析:BigQuery ML 支持以多种方式训练和部署文本模型。例如,您可以使用 BigQuery ML 来识别客户在支持电话中的情绪,或者将产品反馈分类到不同的类别中。如果您是 Python 用户,还可以使用 BigQuery DataFrames 进行 pandas 和 scikit-learn 类似的 API 进行文本分析。
- 使用 PaLM 2 LLM 对文档进行摘要:BigQuery 具有一个 ML.GENERATE_TEXT 函数,调用 PaLM 2 模型生成文本,可用于对文档进行摘要。例如,您可以使用 Document AI 提取客户反馈,并使用 PaLM 2 对反馈进行摘要,全部通过 BigQuery SQL。
- 将文档元数据与存储在 BigQuery 表中的其他结构化数据进行合并:这使您可以将结构化和非结构化数据结合起来,以实现更强大的用例。例如,您可以从在线评论中捕获的反馈中识别出高客户终身价值(CLTV)的客户,或者从客户反馈中列出最受欢迎的产品特性。
// Example of document summarization using PaLM 2
SELECT
ml_generate_text_result[‘predictions’][0][‘content’] AS generated_text,
ml_generate_text_result[‘predictions’][0][‘safetyAttributes’]
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `my_dataset.llm_model`,
(
SELECT
CONCAT(
‘Summarize the following text: ‘,customer_feedback) AS prompt,
*
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.customer_feedback_extractor`,
TABLE `my_dataset.customer_feecback_documents`)
),
STRUCT(
0.2 AS temperature,
1024 AS max_output_tokens));