Cloud Ace 是 Google Cloud 全球战略合作伙伴,在亚太地区、欧洲、南北美洲和非洲拥有二十多个办公室。Cloud Ace 在谷歌专业领域认证及专业知识目前排名全球第一位,并连续多次获得 Google Cloud 各类奖项。作为谷歌云托管服务商,我们提供谷歌云、谷歌地图、谷歌办公套件、谷歌云认证培训等服务。
Google Cloud 于11月9日宣布了 Cloud TPU 平台的两项重要更新:
首先,在最新的 MLPerf™ Training 3.1 结果中,与上一代 TPU v4 相比,TPU v5e 在训练大型语言模型 (LLM) 方面表现出 2.3 倍的性价比提升。
其次,Cloud TPU v5e 现已普遍可用,Singlehost推理和Multislice训练技术也同时提供。这些进步为 Google Cloud 客户带来了成本效益、可扩展性和多功能性,可以使用统一的 TPU 平台来进行训练和推理工作负载。
自今年 8 月份推出以来,客户已经广泛使用TPU v5e进行了各种工作负载,涵盖了AI模型训练和服务领域:Anthropic公司正在使用TPU v5e来高效地扩展其Claude LLM的服务。Hugging Face和AssemblyAI公司分别使用TPU v5e来高效地提供图像生成和语音识别工作负载。此外,Google 还依靠TPU v5e来处理Google Bard等前沿内部技术的大规模训练和服务工作负载。
在 MLPerf Training 3.1 LLM 基准上提供 2.3 倍的性能效率
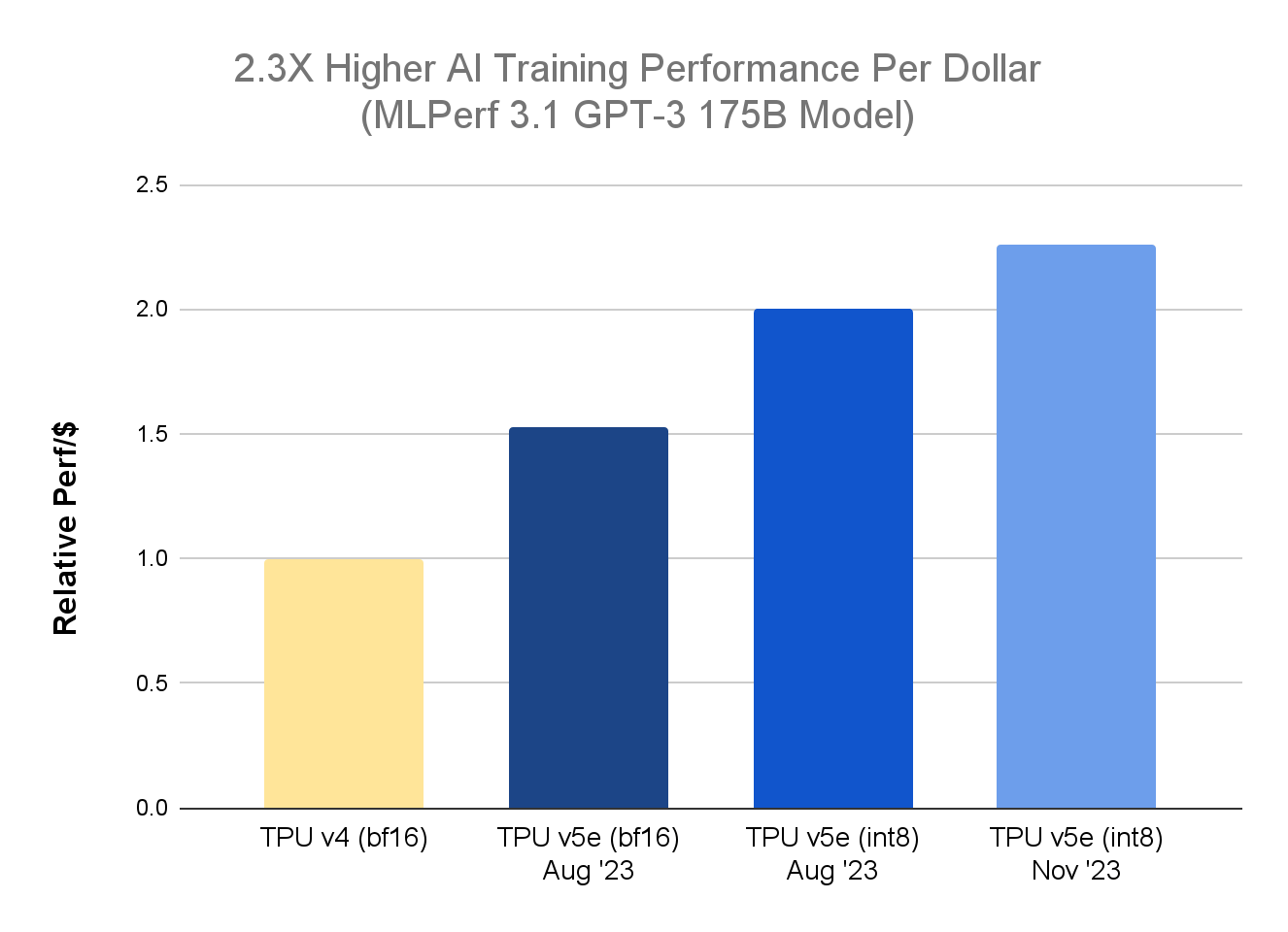 MLPerf™ 3.1 训练 v5e 的封闭结果,TPU v4 的 Google 内部数据。截至 2023 年 11 月:对于 GPT-3 1750 亿个参数模型,每个芯片归一化的所有数字 seq-len=2048 使用 TPU v4 的公开标价(3.22 美元/芯片/小时)和 TPU v5e(1.2 美元/芯片/)的相对性能实现小时)
MLPerf™ 3.1 训练 v5e 的封闭结果,TPU v4 的 Google 内部数据。截至 2023 年 11 月:对于 GPT-3 1750 亿个参数模型,每个芯片归一化的所有数字 seq-len=2048 使用 TPU v4 的公开标价(3.22 美元/芯片/小时)和 TPU v5e(1.2 美元/芯片/)的相对性能实现小时)
利用 Multislice Training 技术扩展到 50000个芯片
Cloud TPU Multislice Training 是一项全栈技术,可以在成千上万个TPU芯片上进行大规模的AI模型训练,为训练大型生成式AI模型提供了一种简单可靠的方法,从而加快价值实现速度并提高成本效率。
最近,我们在 AI 加速器芯片数量最多的情况下运行了世界上最大的分布式 LLM 训练作业之一。利用 Multislice 和 AQT 驱动的 INT8 精度格式,我们扩展到了50,000多个 TPU v5e 芯片,以训练一个32B 参数的密集 LLM 模型,同时实现了53%的 MFU。作为对比,当在6,144个 TPU v4 芯片上训练 PaLM-540B 时,我们实现了46%的 MFU。
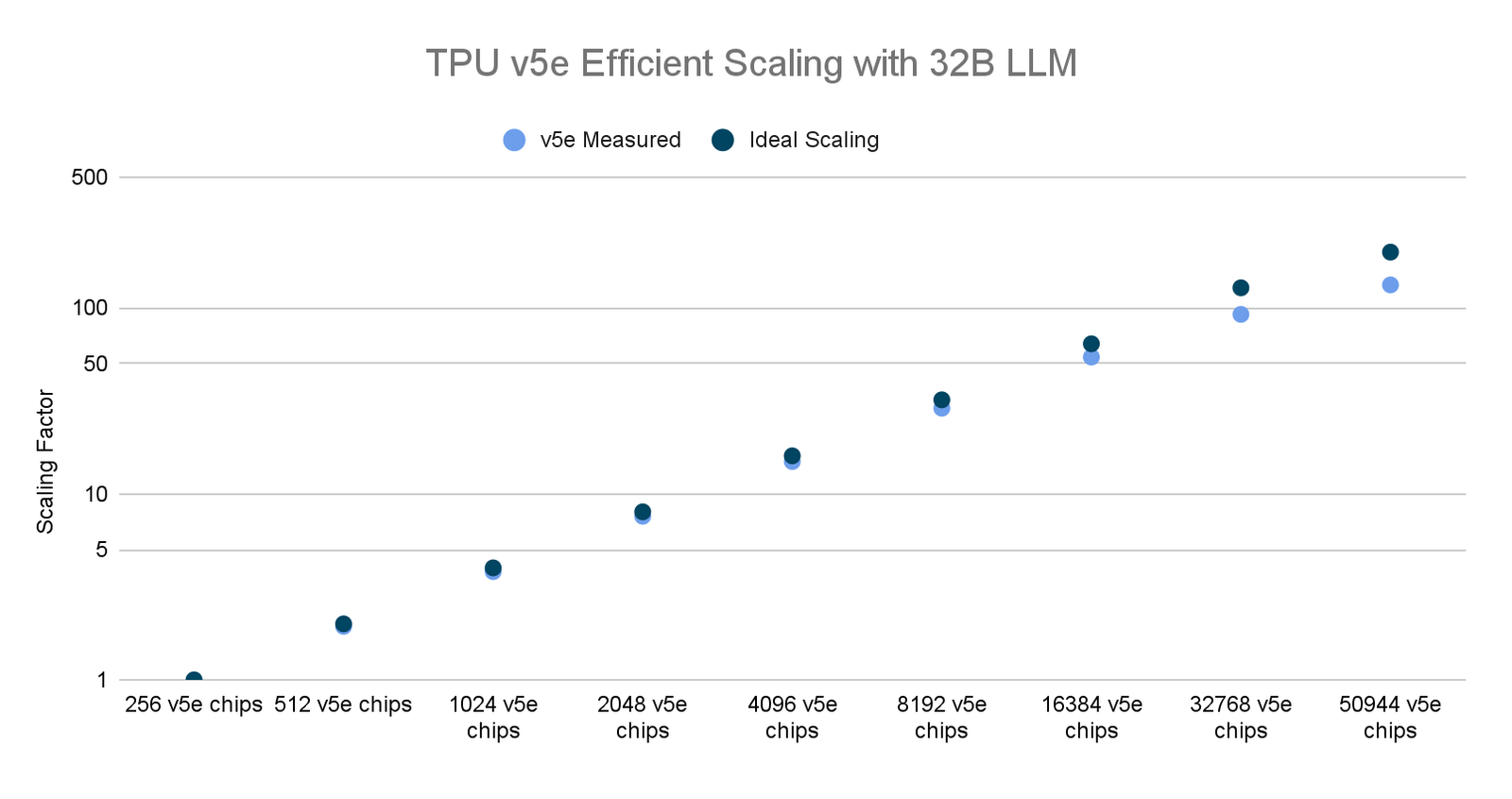 截至 2023 年 11 月,TPU v5e 的 Google 内部数据:每个芯片的所有数字均已标准化。seq-len=2048 用于使用 MaxText 实现的仅 320 亿参数解码器的语言模型。
截至 2023 年 11 月,TPU v5e 的 Google 内部数据:每个芯片的所有数字均已标准化。seq-len=2048 用于使用 MaxText 实现的仅 320 亿参数解码器的语言模型。
客户部署 Cloud TPU v5e 进行 AI 训练和服务
客户依靠大规模的Cloud TPU v5e 集群快速高效地进行前沿LLM的训练和服务。例如,AssemblyAI 正致力于实现前沿AI语音模型的普惠,并在TPU v5e上取得了显著的成果。
AssemblyAI 技术副总裁 Domenic Donato 表示:“最近,我们有机会在GKE上试验 Google 的全新 Cloud TPU v5e,以查看这些专为AI设计的芯片是否能降低我们的推理成本。在真实环境中,在真实数据上运行我们的生产语音识别模型后,我们发现TPU v5e的性价比比其他替代方案高出多达4倍。”
另外,10月初,我们与Hugging Face合作进行了一项演示,展示了使用TPU v5e加速 Stable Diffusion XL 1.0(SDXL)推理的过程。Hugging Face Diffusers 现在支持通过 JAX 在 Cloud TPU 上提供SDXL,从而实现内容创作用例的高性能和高效推理。例如,在文本到图像生成工作负载的情况下,使用八个芯片的 TPU v5e 运行 SDXL 可以在一个芯片生成一张图像的时间内生成八张图像。
Google Bard 团队也在使用Cloud TPU v5e为其生成式AI聊天机器人进行培训和服务。
“自从该平台早期推出以来,TPU v5e 一直为 Bard 的 ML 训练和推理工作负载提供支持。我们非常满意 TPU v5e 的灵活性,它可用于大规模的训练运行(数千个芯片)和高效的 ML 服务,并支持在200多个国家和40多种语言中的用户。”
使用 TPU v5e 为 AI 生产工作负载提供支持
在创新的速度方面,AI 加速、性能、效率和规模继续发挥着至关重要的作用,尤其是对于大型模型而言。现在Cloud TPU v5e已经正式发布,我们迫不及待地想看到客户和生态系统合作伙伴如何突破可能的极限,如果您对此感兴趣,欢迎随时联系我们。