十多年来,IT行业一直在寻找存储和分析海量数据的最佳方法,以处理组织所要求的种类、数量、延迟、弹性和不同的数据访问要求。
从历史上看,企业已经实施了孤岛式的独立架构,数据仓库用于存储结构化的汇总数据,主要用于商业智能和报告,而数据湖用于存储大量的非结构化和半结构化数据,主要用于ML工作负载。这种方法往往导致大量的数据移动、处理和重复,需要复杂的ETL管道。操作和管理这种架构是具有挑战性的,成本很高,而且降低了敏捷性。随着企业向云计算的发展,企业开始希望打破这些孤岛。
为了解决其中的一些问题,出现了一个新的架构选择:数据湖库,它结合了数据湖和数据仓库的关键优势。这种架构以一种开放的格式提供低成本的存储,可被各种处理引擎(如Spark)访问,同时还提供强大的管理和优化功能。
谷歌云为这些客户提供了选择,那些只想使用开源技术建立数据湖心岛的组织,可以通过使用谷歌云存储提供的低成本对象存储,以Parquet等开放格式存储数据,使用Spark等处理引擎,并通过Dataproc使用Delta、Iceberg或Hudi等框架来实现交易,从而轻松做到这一点。这种基于开源的解决方案仍在不断发展,需要在配置、调整和扩展方面做出大量努力。
谷歌云提供了一个云原生、高度可扩展和安全的数据湖库解决方案,为客户提供选择和互操作性。谷歌云的云原生架构降低了成本,提高了企业的效率。
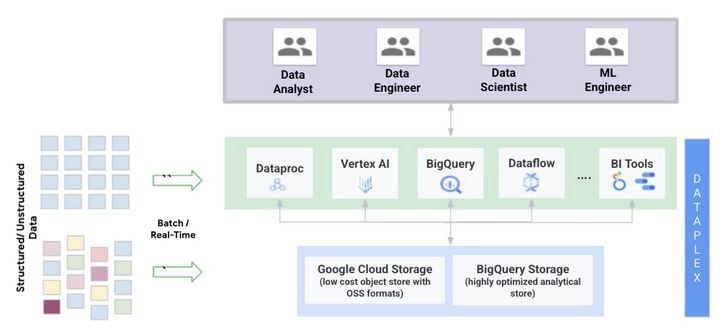
那么谷歌云的解决方案是如何完成的呢?以下为谷歌云搭建数据湖库所依靠的服务:
1.存储:在Google Cloud Storage 中提供低成本对象存储的选择,或在BigQuery中提供高度优化的分析存储。
2.计算:无服务器计算,为不同的工作负载提供不同的引擎
- BigQuery:谷歌云的无服务器云数据仓库提供兼容ANSI SQL的引擎,可以对PB级的数据进行分析。
- Dataproc:管理的Hadoop和Spark服务可以使用各种开源框架。
- Serveless Spark:允许客户将他们的工作负载提交给管理服务,并负责工作的执行。
- Vertex AI,谷歌云统一的MLOps平台,可以用非常有限的编码建立大规模的ML模型。
- 此外,你可以使用谷歌云的许多合作伙伴的产品,如Databricks、Starburst或Elastic,用于各种工作负载。
3.管理:Dataplex在 Cloud Storage(对象存储)和BigQuery(高度优化的分析存储)的数据中实现了以元数据为主导的数据管理结构。企业可以使用Dataplex创建、管理、保护、组织和分析湖心岛上的数据。
让我们仔细看看数据湖心岛架构的一些关键特征,以及客户是如何在谷歌云上大规模地构建这种架构的。
存储的可选择性
谷歌云的核心原则是提供一个开放的平台。谷歌云希望为客户提供选择,将他们的数据存储在谷歌云存储的低成本对象存储或高度优化的分析存储或GCP上的其他存储选项。因此谷歌云建议企业将其结构化数据存储在BigQuery Storage中。BigQuery Storage还提供了一个流媒体API,使企业能够实时摄取大量数据并进行分析。我们建议将非结构化数据存储在Google Cloud Storage。在某些情况下,如果组织需要访问他们的结构化数据的OSS格式,如Parquet或ORC,他们可以将它们存储在 Google Cloud Storage。
谷歌云已经投资建立了Data Lake Storage API,也被称为BigQuery Storage API,为BigQuery和GCS存储层的结构化数据提供一致的功能。该API使用户能够通过任何开源引擎如Spark、Flink等访问BigQuery存储和GCS。Storage API使用户能够对BigQuery和GCS存储中的数据应用细粒度的访问控制(即将推出)。
无服务器计算
数据湖库使企业能够打破数据孤岛并集中数据,这有利于企业间各种不同类型的用例。为了从数据中获得最大的价值,谷歌云允许企业使用不同的执行引擎,针对不同的工作负载和角色进行优化,在同一数据层上运行。由于谷歌云上的计算和存储完全分离,这才成为可能。 满足用户的数据访问水平,包括SQL、Python或更多基于GUI的方法,意味着技术技能不会限制他们使用数据进行任何工作的能力。数据科学家可能在传统的基于SQL或BI类型的工具之外工作。因为BigQuery有 Storage API,所以AI Notebooks、运行在Dataproc上的Spark或Spark Serverless等工具可以很容易地被整合到工作流程中。这里的范式转变是,数据湖库架构支持将计算带到数据上,而不是将数据移动。有了Serverless Spark和BigQuery,数据工程师可以把所有时间花在代码和逻辑上。他们不需要管理集群或调整基础设施。他们从自己选择的界面上提交SQL或PySpark作业,处理过程会自动扩展以满足作业的需要。

BigQuery利用无服务器架构使组织能够使用熟悉的 SQL 界面运行大规模分析。组织可以利用 BigQuery SQL 对 PB 级数据集运行分析。此外,BigQuery ML 让 SQL 从业者使用现有的 SQL 工具和技能构建模型,从而使机器学习民主化。BigQuery ML 是另一个示例,说明如何通过使用熟悉的方言和移动数据的需求来提高客户的开发速度。
Dataproc是 Google Cloud 的托管 Hadoop,可以直接从 Lakehouse 存储读取数据;BigQuery 或 GCS 并运行其计算,然后将其写回。实际上,用户可以根据自己的需要和技能自由选择存储数据的位置和方式以及如何处理数据。Dataproc 使组织能够利用所有主要的 OSS 引擎,如 Spark、Flink、Presto、Hive 等。
Vertex AI 是一个托管机器学习 (ML) 平台,允许公司加速人工智能 (AI) 模型的部署和维护。Vertex AI 与 BigQuery Storage 和 GCS 原生集成,以处理结构化和非结构化数据。它使各个专业水平的数据科学家和 ML 工程师能够实施机器学习操作 (MLOps),从而在整个开发生命周期中高效地构建和管理 ML 项目。
智能数据管理和治理
数据湖库致力于将数据存储在单一真实来源中,从而制作最少的数据副本。一致的安全和治理是任何湖舍的关键。Dataplex是谷歌云的智能数据结构服务,提供跨基于 GCS 和 BigQuery 的各种 Lakehouse 存储层的数据治理和安全功能。Dataplex 使用与底层数据关联的元数据,使组织能够将其数据资产逻辑地组织到湖泊和数据区中。这种逻辑组织可以跨越存储在 BigQuery 和 GCS 中的数据。
Dataplex 位于整个数据堆栈的顶部,以统一治理和数据管理。它提供了一个统一的数据结构,使企业能够通过集成的分析体验智能地管理、保护和管理大规模数据。它提供跨不同系统的自动数据发现和模式推断,并通过将元数据作为表和文件集自动注册到元存储来补充这一点。通过 Dataplex 中的内置数据分类和数据质量检查,客户可以访问他们可以信任的数据。
关于Cloud Ace:
Cloud Ace是亚太地区拥有最多据点的Google Cloud经销商,拥有200多名工程师,是谷歌最高级别合作伙伴,多次获得Google Cloud合作伙伴奖。Cloud Ace专注于提供谷歌云及相关服务,提供从云安装设计到运维的一站式支持。作为谷歌云托管服务商,我们提供技术支持、咨询、系统开发、谷歌云认证培训。Cloud Ace在日本4个城市和越南河内胡志明, 新加坡, 印尼, 泰国, 中国台湾香港深圳等地设有办事处,服务客户超过1000家,并与120多家合作伙伴公司共同推动数据迁移。